
Text mining tools and guide - transform unstructured data into insight
Learn how to use text mining to achieve real business objectives.
August 8, 2021

Some of the main objectives text mining can be used for include:
Information extraction
Summarization and categorization
Sentiment analysis
Visualizing and clustering
Other techniques can be applied beyond these core business objectives, but for most businesses in their day-to-day operations it’s these that will lead to the largest breadth of insights.
What is unstructured data?
First we must understand what unstructured data is, and how we can shape and mold it to fit our business purposes. Unstructured data is everything that touches your business and can be measured. Sometimes, it may already include structure - receipts, payroll, consumer opinion polls, for example.
More often than not the text data you want to use for analysis will not have structure.
Think about things like a giant comment thread on social media, customer surveys with short answer boxes, emails from customers, reviews on third party websites... or anything else your business might care to keep tabs on.
In short, unstructured data is just about everything we can find out in the world. While the examples above limit our analysis to only textual mediums, a dynamic 21st century enterprise cannot afford to keep such blinders on.

Talkwalker's Quick Search applies structure to these unstructured datasets in seconds.
Talkwalker is the best-in-breed consumer intelligence platform to measure and visualize customer experience, text mining, and unstructured data analytics. Talkwalker helps enterprises broaden their horizons by including a vast array of mediums including but not limited to video, images, and audio via podcasts.
Create structured data from unstructured data
Of course boundaries are needed, and the first step to generating powerful insights is to give structure to big, unstructured datasets. This means converting the dataset from whatever medium it exists in its original form (video, audio, image, text) into text.
Talkwalker does this in a variety of ways including by identifying logos in images and videos, but also objects (person, dog, tie, cars, etc.) and scenes (airplane, bar, mountain etc.). And also in audio through speech-to-text conversion. This allows for a broad variety of text documents to incorporate into your data analysis.
When using Talkwalker this process happens behind the scenes and is seamless, appearing before you in seconds. The other alternative is to learn programming languages like R and Python and integrate them into your own machine learning algorithm.
Go from brand cluster headache to brand cluster visualizations
Visualizing unstructured data
Once you tame your dataset and it’s fit for text analysis, you can set about the important business of mining your text and applying natural language processing techniques to it to glean insights about your business, your competitors, or your customer base.
Summarization is one natural language processing and visualization technique you can apply. This helps you to understand the scope of your dataset and can immediately speed up your time to insight from text analysis: if using a customer email dataset for example - how many customer email complaints did you receive this month? Is that number more or less than from last month?
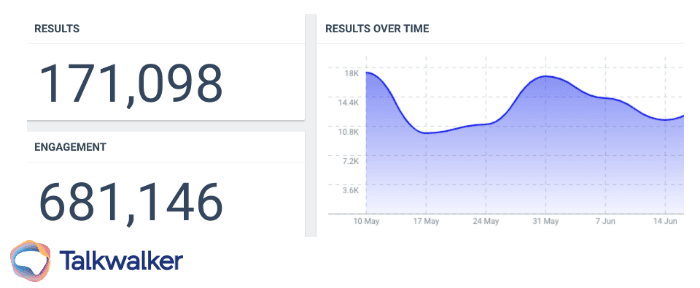
Summarizing the dataset can include measuring total instances of it occurring, a secondary metric occurring like social media engagements, or plotting results over time.
Categorization is another natural language processing technique that can accomplish similar goals. Sticking with the email dataset for example, what amount of emails included an email signature when they wrote to you? From this, can you learn what is the number one title or occupation your customers have? How about the third or fourth most likely occupation?
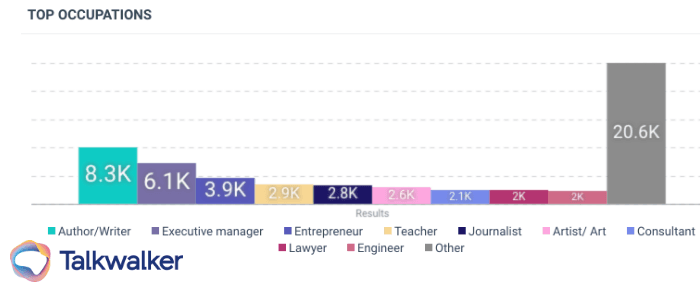
Categorization can help enterprises understand who their customers are.
Clustering is the most visually striking machine learning technique (in my humble opinion), and again the goal here is to generate quick insight. By clustering similarly themed data points in a visualization (1, below), the analyst is able to quickly see and exploit connections between different themes and ideas that may not have any similarity at first glance.
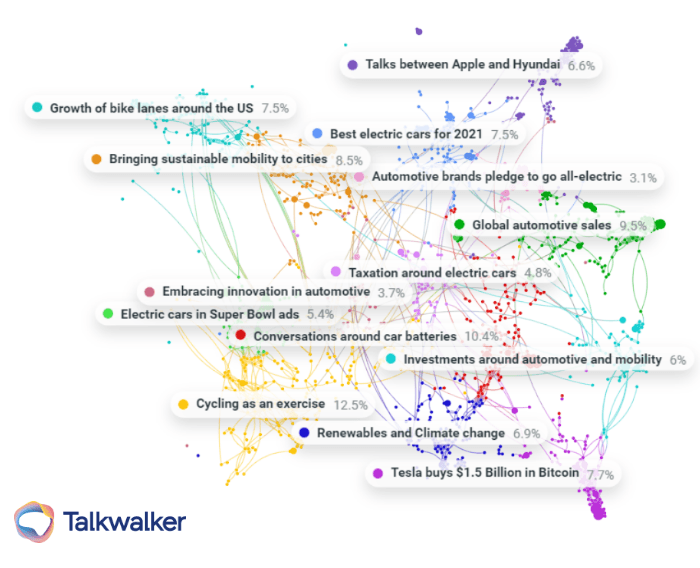
Clustering conversations around green mobility in the United States allows us to draw some interesting connections.
1: Using a natural language processing technique known as n-grams that finds the most common and likely similarly nearby words - it’s the same magic that your phone or Google use to predict your next SMS or search.
Building a data lake data lake for your enterprise: A data lake is a central compository where all the data that could be useful and should be mined for insights by your data scientists and researchers lives. Within it you can apply text mining algorithms and other forms of deep learning algorithms i.e., artificial intelligence and rule based queries to your data models.
Text mining for sentiment analysis
Sentiment analysis for text mining is one of the most powerful techniques to apply to natural language processing. With sentiment analysis applied to structured text data, enterprises can finally answer -- at scale and on a detailed level -- the big question they always want to know: Do people like this?
Now sentiment analysis is tricky on a technical level, but it’s also subjective, making it trickier still. For a brand, a phrase like “that’s sick” could be very positive. Or absolutely not.
That nuance and judgement is difficult to incorporate into natural language processing. We compiled a list of some of the best tools to use for sentiment analysis.
Unstructured data analytics tools
We also made a full list of text analytics tools that you should peruse. It also contains a useful glossary explaining in greater detail some of these text mining concepts like natural language processing and text mining.
Here are three tools I recommend for unstructured data analysis.
Talkwalker Analytics | Open platform for unstructured data visualization
Talkwalker is an open platform, which means that we support just about every variety of dataset and file source imaginable. This allows the data analyst to cross-compare against internal and external, owned, and third-party data sources.
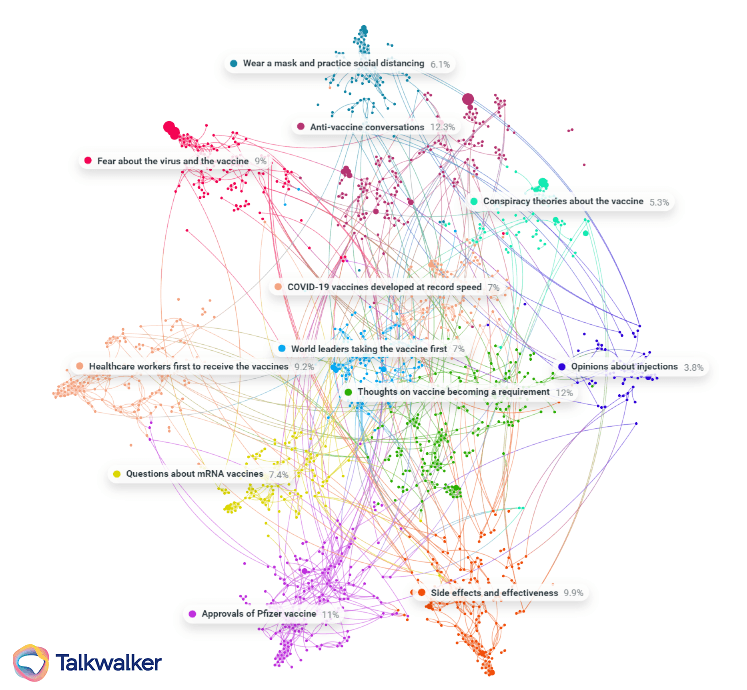
Clustering and visualizing the important topics of conversation in society is easy, and interesting, with the right toolset.
Orange | Open source data mining
This free tool allows for text mining, data mining, visualizations, and more. It contains a lot of features and filters, and also includes visualization support.
Open source machine learning and data visualization.
RapidMiner | Data mining framework
RapidMiner is open source, and provides users with a graphic user interface that includes text processing, web mining, reporting, sentiment analysis, series processing, and more.

RapidMiner offers t_ext processing, web mining, reporting, series processing, plus more._
TEXminer | Free text mining tool
TEXminer is another free and open source tool to support you going from unstructured to structured data analysis. This data analysis tool supports ASCII and PDF formats, and also includes language identification. It also supports co-occurrence analysis, central expressions, and analysis of letter frequency.
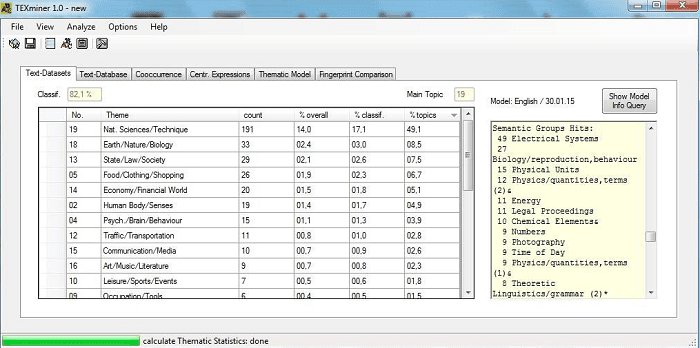
Free text mining tool TEXminer
Takeaway
Wrapping things up, text mining can help apply structure to unstructured datasets. It’s our job as analysts and insights jockeys to help create the boundaries of what we search for so as to be able to give context and meaning to what we find. It’s important to arm yourself with the best tools available. Don’t just focus on impact, focus on connections.
